nginx的reuseport特性分析
1、问题现象
1.1、性能断崖问题
在业务性能测试过程中,发现了一个异常现象:整个压测过程中会出现性能断崖。正常情况下 TPS 维持在 2.8 万左右,但会突然降至 1500 左右,随后立即恢复,但只能恢复到 2.2 万,性能损耗约 20%。
测试架构:
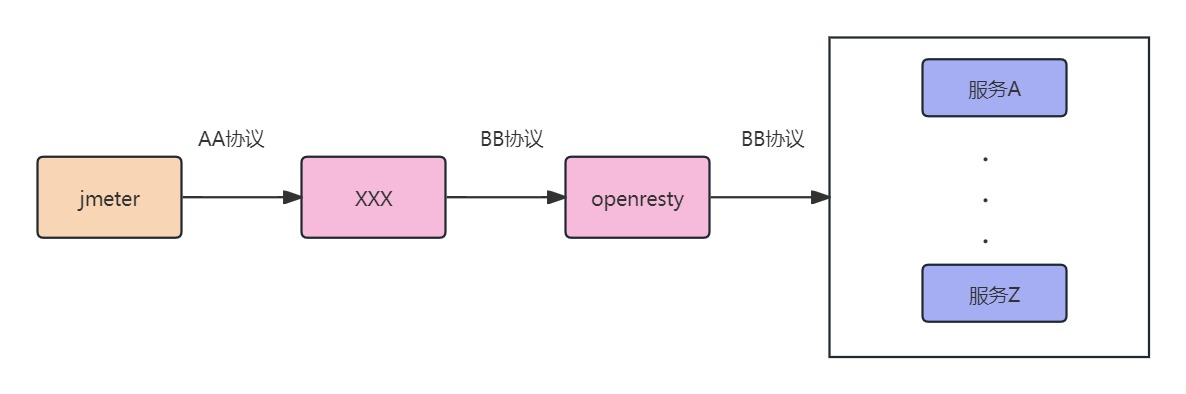
测试环境配置如下:
1 | |
问题特征: 当 Nginx worker 进程数调整为 64,或客户端通道数调整为 64 时,问题不会出现。即 16-64、64-16 配置均正常,但 16-16 配置下 100% 复现断崖问题。
排查过程:
由于现场缺少监控,排查过程较为困难,但通过分析确认了以下问题:
性能瓶颈不在 Nginx:整个压测过程中,Nginx 最大 CPU 使用率仅 45%,主要问题在于性能断崖。
流量下降现象:查看 Nginx 日志未发现报错,但断崖发生时客户端流量明显下降。根据日志绘制的曲线与压力机曲线一致。
问题定位:重点分析客户端流量突降的原因。整个链路中多个节点都可能存在问题:客户端队列阻塞、Nginx 处理变慢、服务端处理变慢等。
关键难点: 由于是私有协议,未启用 access.log,无法获取请求耗时、数量等关键信息。从压力机数据看,64 个进程和 16 个进程的平均时延无明显差异。流量数据是通过开启 debug 日志并手动统计日志条数获得的。因此开始使用 tcpdump 抓包分析,单个抓包文件达到 21GB。
问题解决: 第二天分析抓包数据前,发现是信创系统,检查 Nginx 版本后发现版本不适配。更换适配版本后,16-16 配置下断崖问题消失,TPS 提升至 3.2 万(提升 4000),达到数据库分区瓶颈。断崖问题已解决,但操作系统不适配导致断崖的根因待进一步分析。
新发现的问题: 压测过程中,Nginx 各进程压力不均衡,进程压力呈递减状态。
1.2、Worker 进程连接数不均衡
我们有两种私有协议,可理解为 TCP + 自定义数据格式 和 TCP + JSON。这类协议的客户端和服务端会建立长连接(通常称为通道),后续请求均通过该通道传输。
复现测试: 为更直观地复现问题,将 Nginx 配置为 64 个 worker 进程,应用与 Nginx 建立 64 条连接。使用 netstat 命令统计连接数,结果如下:
- Nginx 共有 64 条连接
- 39 个 Nginx 进程有连接,25 个进程处于空闲(无连接)
- 连接数分布:
- 1 个进程:4 条连接
- 5 个进程:各 3 条连接
- 14 个进程:各 2 条连接
- 19 个进程:各 1 条连接
- 25 个进程:0 条连接
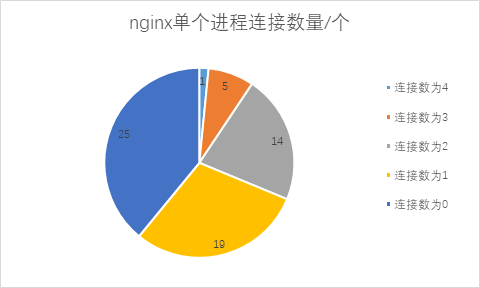
压力分布特征: 压测过程中,共有 39 个 Nginx 进程有压力,且压力大小与进程连接数成正比。例如,一个进程拥有 4 条连接,另一个进程拥有 1 条连接,压力比约为 4:1。现场反馈的”递减”现象正是此现象。那么为什么连接数会不一致?
1.3、HTTP 协议下的不均衡现象
既然私有协议存在连接数不均衡问题,接下来测试 HTTP 协议。直接使用 HTTP 协议连接 Nginx,配置更新如下:
1 | |
测试架构:
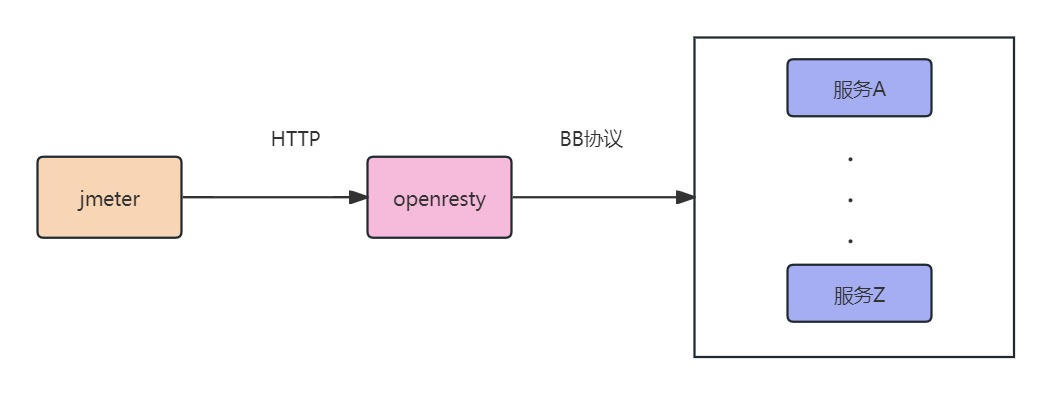
测试结果: Nginx 压力依旧不均衡,仅有十几个进程有压力,CPU 使用率维持在 60%~90%。此时 TPS 已达到 8 万+,瓶颈在数据库。因此需要深入研究 Nginx 建立连接的机制。
2、基础知识
2.1、epoll 基础
epoll 是 Linux 内核提供的高效 I/O 事件通知机制。典型的 epoll 使用流程如下(参考示例:https://github.com/ZJfans/EpollET-Server/blob/master/epollET.c):
- 初始化监听套接字:创建并绑定监听套接字
- 创建 epoll 实例:调用
epoll_create创建 epoll 文件描述符 - 注册监听套接字:使用
epoll_ctl将监听套接字添加到 epoll 实例 - 事件循环:使用
epoll_wait循环等待事件 - 处理事件:
- 如果触发的是监听套接字,则调用
accept建立新连接 - 如果触发的是客户端套接字,则处理读写事件
- 如果触发的是监听套接字,则调用
2.2、Nginx 工作模式(与 muduo 对比)
Nginx 多进程模式:
- Nginx 采用多进程架构
- 初始化时,Master 进程监听端口
- Master 进程 fork 多个 Worker 进程
- 所有 Worker 进程共享同一个监听套接字
muduo 多线程模式(对比):
- muduo 采用多线程架构
- 主线程负责处理监听套接字的事件
- 建立连接后,将连接分配给 Worker 线程
- 后续的读写事件均由 Worker 线程处理

3、SO_REUSEPORT 与惊群效应
3.1、惊群效应(Thundering Herd)
惊群效应是多进程或多线程系统在等待同一事件时可能遇到的问题。在网络编程中,尤其是在使用 epoll 进行 I/O 多路复用时,惊群效应可能导致性能问题。
产生原因:
当多个进程同时等待新的网络连接请求时,如果事件发生(例如新连接到达),所有等待的进程都会被唤醒。但最终只有一个进程能够处理该事件(通过 accept 系统调用接受连接),其他进程在尝试处理事件失败后会重新进入等待状态。这个过程会导致大量的上下文切换和 CPU 资源浪费。
Nginx 的解决方案:
Nginx 采用以下几种策略来避免或减少惊群效应的影响:
accept_mutex(接受互斥锁):- Nginx 可以使用
accept_mutex来同步对accept调用的访问 - 在任何给定时间,只有一个 Worker 进程可以处理新的连接请求
- 通过在工作进程之间引入互斥锁,避免多个进程同时尝试接受同一个连接
- 在配置文件中设置
accept_mutex on可启用此功能
- Nginx 可以使用
EPOLLEXCLUSIVE(独占唤醒):- Linux 内核 4.5 版本引入的标志
- Nginx 从 1.11.3 版本开始支持
- 使用
EPOLLEXCLUSIVE标志添加 epoll 事件时,内核保证事件发生时只唤醒一个等待的进程 - 减少因多个进程监听同一个文件描述符而产生的惊群效应
SO_REUSEPORT(端口复用):- Linux 内核 3.9 版本引入的套接字选项
- Nginx 从 1.9.1 版本开始支持
- 允许多个进程绑定到相同的端口上
- 内核在多个监听相同端口的进程之间进行负载均衡
- 新连接请求到达时,内核根据一定规则选择一个进程处理,避免多个进程同时被唤醒
3.2、SO_REUSEPORT 原理
SO_REUSEPORT 是 Linux 内核级别的套接字选项,允许多个套接字(通常是监听套接字)绑定到相同的网络地址和端口上。该特性在 Linux 3.9 版本中引入,主要用于解决多进程或多线程环境中的惊群效应问题。
传统端口绑定的限制:
在 SO_REUSEPORT 出现之前,根据 POSIX 标准,一个网络端口在同一时间内只能被一个套接字绑定。如果有多个进程想要监听同一个端口,必须使用同步机制(如互斥锁)来协调对端口的访问,这可能导致性能问题和复杂的编程模型。
SO_REUSEPORT 的突破:
SO_REUSEPORT 选项打破了这一限制,允许多个套接字监听同一个端口,无需特殊的同步机制。当启用 SO_REUSEPORT 时,内核会在内部进行负载均衡,将到达的数据包分发给监听该端口的多个套接字。
实现原理:
端口复用:
- 多个进程或线程的套接字启用
SO_REUSEPORT并绑定到同一端口时,内核为每个套接字创建独立的接收队列 - 所有到达的数据包(如新的连接请求)根据负载均衡算法在这些队列之间分配
- 多个进程或线程的套接字启用
负载均衡:
- 内核使用负载均衡算法(通常是哈希算法)决定哪个套接字接收特定的连接请求
- 即使多个进程监听同一端口,每个进程也只会接收一部分连接请求,而非全部
并发处理:
- 每个进程拥有独立的接收队列,可并发处理连接请求,互不干扰
- 显著减少进程间的上下文切换和竞争,提高系统并发处理能力
安全性和隔离:
- 多个套接字绑定到同一端口,但通信相互隔离,每个套接字只能处理分配给它的数据包
SO_REUSEPORT要求所有绑定到同一端口的套接字必须属于同一用户,以避免潜在的安全问题
3.3、负载均衡算法概述
内核从监听哈希表中查找匹配的套接字时,关键函数是 compute_score,它为每个 socket 计算一个权重值(得分)。这类似于 Nginx 的轮询算法,根据算法得出同一个 upstream 下每个 server 的权重,将请求分配给权重最大的 server。
重要说明: 当开启 SO_REUSEPORT 后,内核会直接调用 inet_lookup_reuseport,该函数直接选择 socket,选择到即返回。具体分析见第 4 节。
1 | |
3.4、Nginx 版本差异导致的异常现象
问题发现: 如果 Nginx 有 4 个进程监听同一端口,为什么连接分配会不均匀?使用自定义 Nginx 进行测试:
- 不开启 reuseport:多个进程共享一个 socket
- 开启 reuseport:4 个进程,每个进程都监听了 4 个 socket?
为什么不是 4 个进程各自监听自己的 socket?
排查过程:
内核版本问题?
- 测试环境内核版本为 3.1(较低)
- 更换为 4.19 内核,现象依然存在
- 结论: 不是 Linux 内核版本问题
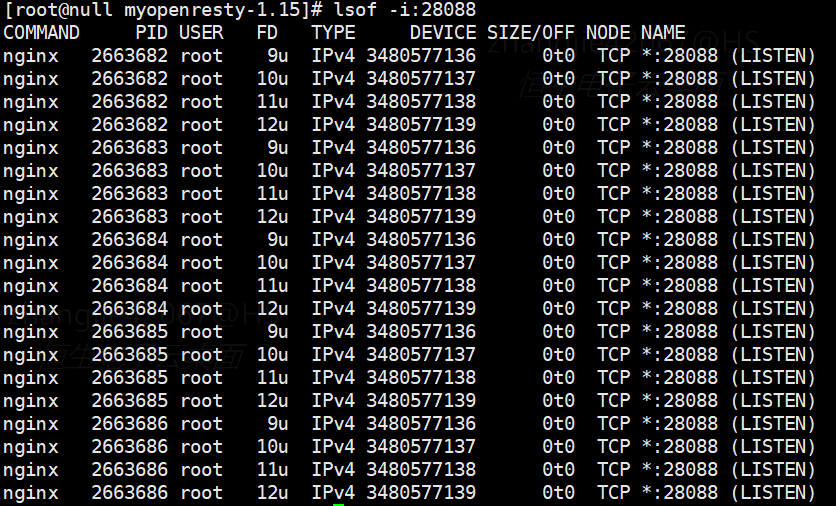
Nginx 版本问题?
- 测试版本:OpenResty 1.15.8(对应 Nginx 1.15.8)
- 升级到 OpenResty 1.25.3,重新编译启动后,Worker 进程行为符合预期
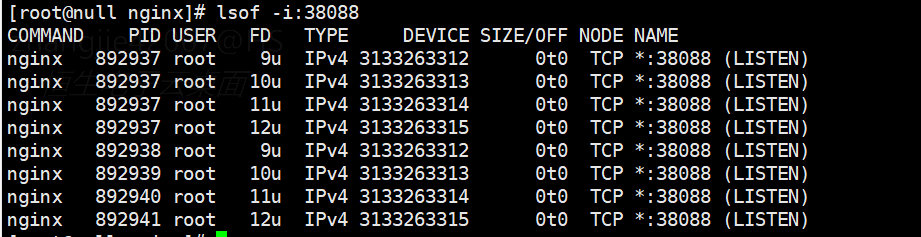
代码对比分析:
对比两个版本的代码,发现新版本确实做了优化:会关闭多余的 socket。
重要说明: lsof -i 显示的结果仅表示绑定关系。Nginx 1.15.8 版本的进程虽然绑定了多个 socket,但并未监听每一个,即没有将每个 socket 添加到 epoll 中。
代码对比:
Nginx 1.15.8 版本:
1 | |
Nginx 1.25.3 版本:
1 | |
关于 Master 进程绑定多个 socket 的问题:
问题: Master 进程为什么也绑定了 4 个 socket?accept 事件到来时,Master 进程也会触发吗?
答案: 无需担心。Master 进程不会将这些 socket 添加到 epoll 中,因此永远不会触发 accept 事件。
能否删除 Master 进程的绑定?
Nginx 的重启依赖于 Master 进程 fork Worker 进程。Master 进程的 socket 不能丢弃,原因可能是:
reload时需要重新创建 socket,如果丢弃可能导致之前的状态丢失- 停止时需要关闭 socket,Master 进程需要知道当前打开的句柄数
此问题有待进一步分析。
4、Linux 内核源码分析
本节分析 Linux 内核如何实现 SO_REUSEPORT。该特性在 Linux 内核 3.9 版本中引入。本文基于两个版本的内核代码进行分析:广泛使用的 4.19 版本和最新的 6.8 版本。
说明: 6.8 版本的代码结构更清晰直观,以下注释基于该版本。
1 | |
那么重点是2个地方
4.1、compute_score
4.1.1、compute_score 函数
compute_score 函数类似于 Nginx 的轮询算法,为每个 socket 计算权重(得分),根据权重/分数进行事件分发。
1 | |
得分计算逻辑:
score 在 3 个地方会发生变化。连接会分发给哪个 socket,取决于这 4 个 socket 在哪些方面不同,导致得分不同(对应 4 个 Nginx 进程)。
设备接口绑定检查:
- 检查套接字是否绑定到指定的设备接口,设备接口是否匹配差异接口
- 这对应网卡绑定。对于 Nginx 的 4 个进程,如果都监听所有网卡,则 4 个进程的 socket 得分都是 1,无差异
1
2
3
4
5
6
7
8
9server {
listen 38088 reuseport;
server_name example.com;
location / {
root /usr/share/nginx/html;
index index.html index.htm;
}
}IPv4 类型加分:
- 如果套接字是 IPv4 类型,额外加 1 分
- 在仅考虑 IPv4 地址的场景下,虽然也监听了 IPv6,但 4 个进程的 socket 得分都加 1,无差异
CPU 亲和性加分:
- 如果接收数据包的 CPU 与当前 CPU 相同,额外加 1 分
sk_incoming_cpu 字段说明:
在 sock_reuseport.c 模块中,sk_incoming_cpu 是套接字结构中的一个字段,它记录了最近处理该套接字传入数据的 CPU 核心。当新的数据包到达时,操作系统会尝试将数据包分配给记录在 sk_incoming_cpu 中的 CPU 核心来处理,以优化性能。
4.1.2、CPU 与套接字的关系
数据包处理流程:
- 数据包到达:网络数据包到达时,首先被网络接口卡(NIC)捕获,通过中断通知 CPU
- 中断处理:CPU 接收中断后,操作系统的中断处理程序捕获事件并开始处理数据包
- 套接字绑定:网络栈根据数据包的目标地址和端口号,决定将数据包发送到哪个套接字
- CPU 亲和性(CPU Affinity):在多核 CPU 系统中,操作系统可能将特定的套接字或网络流量绑定到特定的 CPU 核心,目的包括:
- 缓存利用:套接字在同一 CPU 核心上处理数据时,相关数据结构和状态信息更可能保留在该核心的 CPU 缓存中,减少内存访问延迟
- 减少上下文切换:数据包处理在同一核心上进行,减少不同 CPU 核心之间的上下文切换
- 负载均衡:将不同的套接字或网络流量分配给不同的 CPU 核心,实现更好的负载均衡
关键时机:TCP 三次握手
重要的是第一个网络包到达时的处理。让我们看看 TCP 三次握手过程:
- 客户端发送 SYN 包:客户端发送 SYN(同步)包给服务端,包含客户端的初始序列号
- 服务端接收 SYN 包并创建 socket:服务端收到 SYN 包后,分配资源并创建用于与客户端通信的 socket,为该连接分配序列号和缓冲区等资源
- 服务端发送 SYN-ACK 包:服务端发送 SYN-ACK 包给客户端,包含服务端的序列号以及确认号(客户端序列号加一)
- 客户端发送 ACK 包:客户端收到 SYN-ACK 包后,发送 ACK(确认)包给服务端
- 连接建立完成:服务端收到 ACK 包后,连接建立完成,可以开始数据传输
关键点: 服务端在接收到客户端的 SYN 包后,会创建用于与客户端通信的 socket,此时会更新 sk_incoming_cpu。下次该 CPU 分配连接时,会优先分配给该 CPU 处理过的 socket,即额外加 1 分。
1 | |
4.1.3、更新sk_incoming_cpu
重要的是reuseport_update_incoming_cpu,如何设置和更新sk_incoming_cpu
1 | |
理解了 sk_incoming_cpu 后,就可以理解得分计算机制。但事实上,开启 SO_REUSEPORT 后,socket 选择的核心函数是 inet_lookup_reuseport。
4.2、inet_lookup_reuseport
1 | |
计算完得分后,如果找到了匹配的 socket,则直接返回。接下来分析 inet_lookup_reuseport 的实现。
4.2.1、inet_lookup_reuseport源码
1 | |
最后是调用了reuseport_select_sock
1 | |
实际的选择
1 | |
数据结构说明:
reuse->socks[i]:一个指针数组,存储一系列struct sock指针。每个指针代表一个网络套接字,这些套接字都绑定到同一端口并启用了SO_REUSEPORT特性num_socks:表示socks数组中当前有效的套接字(struct sock指针)数量,用于跟踪监听同一端口并启用SO_REUSEPORT特性的套接字数量
4.2.2、选择算法总结
reuseport_select_sock_by_hash 函数的执行流程:
- 计算哈希值:根据
net、daddr、hnum、saddr和sport参数计算哈希值 - 计算起始索引:使用哈希值和 socket 数量计算
reuse->socks数组的起始索引 - 检查空闲状态:判断当前 socket 是否有连接请求在处理。如果没有,说明该监听 socket 目前空闲,选择该 socket
- 检查 CPU 亲和性:如果步骤 3 未返回,判断
sk_incoming_cpu。如果该 socket 上一次数据是当前 CPU 处理的,则选择该 socket - 保底选择:如果该 socket 不满足条件,将其设置为保底选择
- 循环处理:循环执行步骤 3-5
- 返回结果:遍历完
reuse->socks数组中的所有 socket 后,返回第一个有效的 socket;如果未找到,返回 NULL
5、总结
5.1、原理总结
对于内核而言,整个连接分配过程处于传输层,无需关注应用层。内核会最大化优化处理速度,仅考虑传输层属性。主要优化点包括:
- 优先使用空闲的监听 socket
- 使监听 socket 尽量在同一 CPU 处理,有利于 CPU 缓存的利用
开启 SO_REUSEPORT 后,socket 能否获得连接取决于 3 个因素:
- 哈希起始位置:根据哈希值和 socket 数量计算
reuse->socks数组的起始索引,起始位置的 socket 具有优先优势 - 空闲状态:当前 socket 是否处于空闲状态
- CPU 亲和性:上一次处理该 socket 数据的 CPU 是否是当前 CPU
5.2、连接分配是否均匀?
5.2.1、不会绝对均匀
当同一个客户端与同一个 Nginx 建立 64 条长连接时,上述因素 1 中的哈希值和 socket 数量是相同的,因此数组的起始索引是相同的。
连接分配给哪个进程取决于因素 2 和 3。当 64 条连接绝对同时到达,且 Nginx 的 socket 此时没有其他连接(处于空闲状态)时,因素 2 会保证每个 socket 拿到 1 条连接。但问题是:绝对同时?还要保证没有连接到这些 socket?这是不可能的。
因为连接总会有先后顺序,即数据包会先后到达。第一个 socket 处理完第一个连接后,又处于空闲状态,因此它还会继续获得连接。这是因为它具有优势(起始索引计算的结果)。
5.2.2、会发生极限场景吗?
问题: Nginx 开启 64 个进程,是否会出现只有几个进程能拿到连接的情况?
答案:可能性几乎为 0。 因为连接虽然有先后,但时间差非常小,所以都会在因素 2 中分发。除非客户端每隔一段时间发送一个请求。实际上,客户端建立连接时会”同时”发送,但由于存在时间差,前面的 socket 会拿到更多的连接。
补充说明: 当连接数量级足够大时,分配会近似均匀。但当只有几十个连接时,虽然也是近似均匀,但差距看起来会比较大,毕竟有些 socket 拿不到连接,即有些 Nginx 进程拿不到连接。
5.2.3、应用层保证连接数均匀的可行性
问题: 如果想在应用层保证连接数均匀,可以实现吗?
分析: 从可行性和性能两个角度考虑:
可行性:
- 应用层如何判断进程当前拥有多少个长连接?
- 如何区分真正的长连接(TCP 层)和 WebSocket 这种应用层长连接?
性能:
- 如果每次建立连接都需要判断是否是长连接,并均匀分发到各个进程,性能会断崖式下降
结论: 无法实现,也没有意义。
5.2.4、是否需要做连接的均匀分发?
实际情况: 根据实际统计,64 个进程中有 39 个进程拿到连接,即 39 个进程在工作。
问题: CPU 只会利用 39 个核心吗?
答案:不是的。 因为 Worker 进程使用 CPU 时会切换。这也是压测到极限时,CPU 利用率会超过 100%(某些 Java 服务甚至会达到几千)。因此,Nginx 的 CPU 利用率是最大化的,只不过存在 CPU 切换的损耗,基本可以忽略不计。
结论: 当压力达到 Nginx 极限时,不同进程的 CPU 利用率会有差异,但一定会利用到所有 CPU,即可以发挥机器的最大性能。